機械学習により有望物質群とその設計指針を抽出
-所望の特性を持つ無機材料のパターンを自動検出する手法を開発-
要点
● 無機材料データから所望の光学特性を持つ物質群に共通な特徴を検知
● 機械学習予測モデルに基づいたクラスタリングにより物性を考慮した物質分類を実現
● マテリアルズインフォマティクスにより物質・材料科学的な知識を獲得
概要
所望の材料機能の発現の鍵となる構成元素や原子配列の特徴を見出すことは、材料設計指針の構築や機能発現機構の解明において重要です。本手法は、機械学習の物性予測モデルに基づいて物質の分類を行うことにより、物質群・物性の種類を問わず、任意の無機材料データから所望の物性に応じて有望な物質のパターンを抽出することを可能にしました。これにより、1,000種類以上の物質を含む無機材料データから各エネルギー領域のバンドギャップを持つ物質や、広いバンドギャップと大きい屈折率を両立する物質に共通な特徴を事前知識無しに自動的に検知することに成功しました。本手法によりマテリアルズインフォマティクス(用語1)を用いた物質・材料科学的な知識の獲得が明確・容易になり、さまざまな無機材料の研究・開発や学理構築が加速されることが期待されます。
本研究成果は8月5日付(現地時間)で「Advanced Intelligent Systems」誌に掲載されました。
背景
材料科学分野では、物質の構成元素や原子配列の特徴に着目し、一定の基準において物質をさまざまな物質群に分類することが頻繁に行われてきました。例えば金属と酸素の化合物であるシリカ(SiO2)やアルミナ(Al2O3)は酸化物という物質群にまとめられ、窒化物や硫化物などと区別して取り扱われます。また価電子構造に基づいたII-VI族半導体(CdTe、ZnSe、ZnOなど)、III-V族半導体(GaAs、GaP、GaN、AlNなど)といった分類や、結晶構造の観点で岩塩型構造やペロブスカイト型構造といった分類を用いながら、材料設計指針や機能発現機構についての議論が行われてきました。一般に材料設計指針や機能発現機構について考える際に、あらかじめ有望な物性を持つ物質群やその構成元素・原子配列の特徴を知ることができれば有益です。
ある機能を発現する鍵となる特徴や望ましい機能を持つ有望物質群は、想定している物性(例えば電気特性、光学特性、磁気特性、力学特性)や、材料の用途(電子材料、光学材料、磁性材料、構造材料など)に応じてさまざまです。したがって構成元素・結晶構造のどういった特徴・基準を用いるかについて無数の分類法が考案されており、所望の機能発現の鍵となる物質の構成元素・原子配列の特徴と、有望な物質群をその都度見出すことが必要となります。
一方で、近年は機械学習がさまざまな分野で爆発的に流行しており、材料科学分野も例外ではありません。最も典型的な応用の一つは、物質の化学式や結晶構造から物性を高速に予測することであり、ここ20年ほどで非常に多くの研究例があります。このような研究では多数の物質について物性値を算出した結果をまとめた第一原理計算(用語2)データベースがよく使われます。さらに最近では、機械学習によりデータを解釈・説明する手法も流行しており、大規模データから構成元素や結晶構造の特徴と物性の関連性を人間が理解できる知識として抽出するための手法も提案されています。例えば、クラスタリング(用語3)と呼ばれるデータ分類法を用いると、あらかじめ人間が選択した特徴量(用語4)について類似した物質群の分類が可能となります。しかし、通常のクラスタリング手法を適用した場合、あらかじめ構成元素・原子配列の特徴量を選択する必要があるため、上述したような用途に応じた物質分類を事前知識無しに行うことができないという問題があります。そこで本研究では、機械学習による物性・機能予測とクラスタリング手法を融合させることで、専門的な事前知識を必要とせずに、想定している物性と物質の構成元素・原子配列に基づいて合理的かつ自動的に物質群の分類を定義する手法を開発することとしました。
研究成果
通常、ランダムフォレストの予測モデルは多数の決定木(用語5)から構成されていますが、まずは本手法の概要を説明するために、1本の決定木で分類が行われる様子を図1に示します。決定木は特徴量を用いた不等式から構成されており、例えば、図1では原子番号や原子間距離に基づいて各物質に物性値パターンを割り当てています。ある物性に関するデータを学習した決定木における不等式で使われる特徴・基準は、その物性を予測する上で適切なものが自動的に選択されます。したがって、興味ある物性データを学習した決定木上で「同じ経路を辿った物質は類似度が高い」、「そうでないものは類似度が低い」と定義して物質の分類を行えば、対象とする物性に対して適切な基準で構成元素・原子配列の類似度を定義し、また類似度の高い物質をまとめて物質群を定義できるというのが本手法の骨子となるアイデアです。
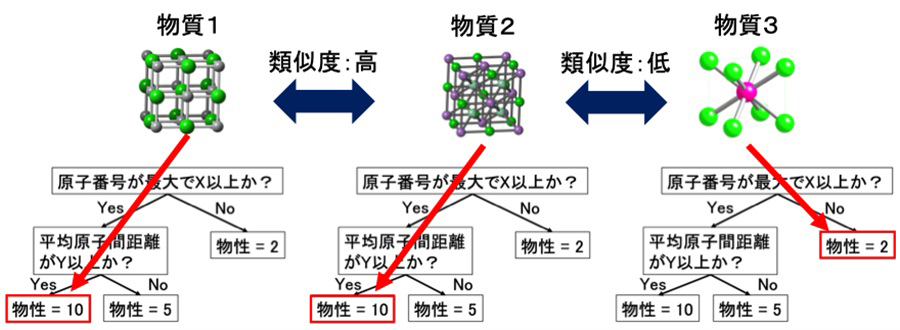
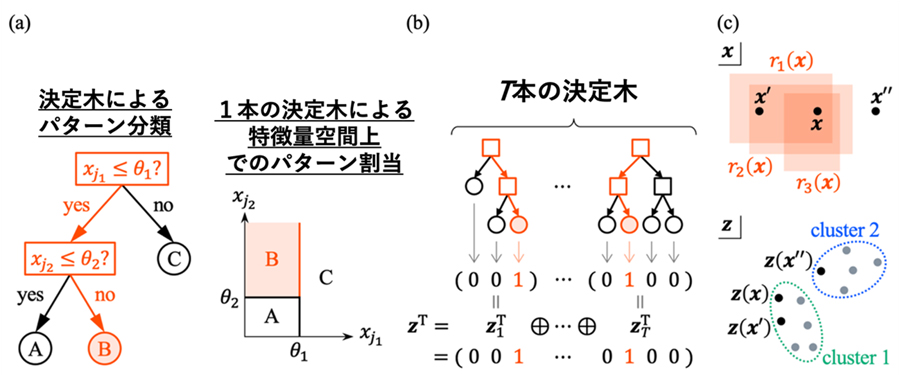
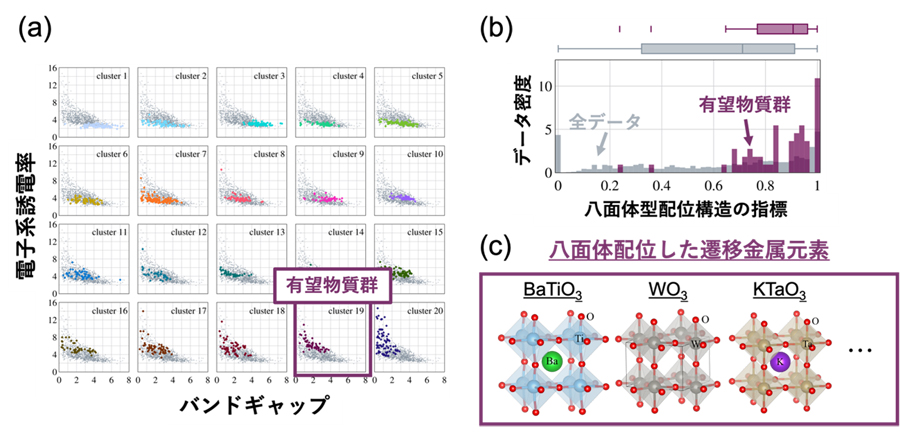
本研究では電子系誘電率に基づいてクラスタリングを行い、取得した酸化物データを20種類に分割することで図3(a)のような結果が得られました。それぞれのクラスターで確かに電子系誘電率の値が類似した物質がまとまっている傾向が確認でき、そのうちの一つの物質群が比較的広いバンドギャップを持ちながら大きな電子系誘電率を持つことが分かります。さらにその物質群の特徴量の分布を全データと比較することで、有望物質群を特徴づける因子を特定しました。例えば図3(b)に示すように、八面体型配位構造が含まれるかどうかの指標に着目すると、全データの分布と比べて有望物質群が明らかに高い値を持つ傾向があることが分かります。このような解析から、この物質群の分類基準は解釈しやすいように簡略化して言えば「八面体配位した遷移金属元素が結晶構造に含まれること」であることが分かりました。実際、図3(c)で示すように、この物質群はペロブスカイト型構造やその類似構造を多く含んでおり、確かに「八面体配位した遷移金属元素」を有していることが分かります。さらにこうした物質の電子状態密度の第一原理計算データについて詳細な解析を行うことで、八面体配位したカチオンがバンドギャップの上端(伝導帯の下端)近傍の電子状態の起源となっており、広いバンドギャップと高い誘電率を両立するための鍵となる因子であることが裏付けられました。
社会的インパクト
今後の展開
研究費
用語説明
(2)第一原理計算:量子力学の基本原理に基づいた理論計算。物質の電子構造やエネルギーを計算することにより、電子・光学・磁気特性や安定性、力学特性など非常に多様な物性や分子・結晶などの構造を予測することができる。
(3)クラスタリング:機械学習の手法の一つで、類似した特徴を持つデータ点をグループ(クラスター)にまとめる方法。
(4)特徴量:機械学習モデルに入力するデータの特徴を表す属性。例えば、材料科学における物性予測では、電気陰性度や近接原子間距離などの原子および原子配列の基礎的な特徴を用いることが多い。決定木予測モデル構築のアルゴリズムでは、学習データから物性予測のために適切な特徴量が自動的に選択される。
(5)決定木:データの特徴に基づいて不等式を繰り返しながらそれぞれのデータに特性のパターンを割り当て、特性の予測を行う機械学習の手法。
(6)one-hot encoding:カテゴリー型データを数値データに変換する手法。各カテゴリー(本研究では決定木により割り当てられたパターン)を0と1の組み合わせで表現する。
(7)Materials Project データベース:材料科学分野の大規模オープンデータベース。第一原理計算により得られた物質の構造や特性に関するさまざまな情報を提供しており、2024年7月時点で15万種類以上の無機物質データを掲載している。(https://next-gen.materialsproject.org)
(8)matminerコード:材料データの取得、処理、機械学習用の特徴量抽出を行うためのPythonライブラリ。材料科学とデータ科学を橋渡しし、マテリアルズインフォマティクスの研究を支援するツール。(https://hackingmaterials.lbl.gov/matminer/)
論文情報
論文タイトル:Target Material Property-Dependent Cluster Analysis of Inorganic Compounds(対象物性に依存した無機化合物のクラスター分析)
著者:Nobuya Sato, Akira Takahashi, Shin Kiyohara, Kei Terayama, Ryo Tamura, Fumiyasu Oba(佐藤暢哉、高橋亮、清原慎、寺山慧、田村亮、大場史康)
DOI:https://doi.org/10.1002/aisy.202400253
お問い合わせ先
mail:koho@yokohama-cu.ac.jp